Code
import pandas as pdThis notebook showcases one possible use of gingado by estimating economic growth across countries, using the dataset studied by Barro and Lee (1994). You can run this notebook interactively, by clicking on the appropriate link above.
This dataset has been widely studied in economics. Belloni, Chernozhukov, and Hansen (2011) and Giannone, Lenza, and Primiceri (2021) are two studies of this dataset that are most related to machine learning.
This notebook will use gingado to compare quickly setup a well-performing machine learning model and use its results as evidence to support the conditional convergence hypothesis; compare different classes of models (and their combination in a single model), and use and document the best performing alternative.
Because the notebook is for pedagogical purposes only, please bear in mind some aspects of the machine learning workflow (such as carefully thinking about the cross-validation strategy) are glossed over in this notebook. Also, only the key academic references are cited; more references can be found in the papers mentioned in this example.
We will import packages as the work progresses. This will help highlight the specific steps in the workflow that gingado can be helpful with.
import pandas as pdThe data is available in the online annex to Giannone, Lenza, and Primiceri (2021). In that paper, this dataset corresponds to what the authors call “macro2”. The original data, along with more information on the variables, can be found in this NBER website. A very helpful codebook is found in this repo.
from gingado.datasets import load_BarroLee_1994
X, y = load_BarroLee_1994()The dataset contains explanatory variables representing per-capita growth between 1960 and 1985, for 90 countries.
X.columnsIndex(['Unnamed: 0', 'gdpsh465', 'bmp1l', 'freeop', 'freetar', 'h65', 'hm65',
'hf65', 'p65', 'pm65', 'pf65', 's65', 'sm65', 'sf65', 'fert65',
'mort65', 'lifee065', 'gpop1', 'fert1', 'mort1', 'invsh41', 'geetot1',
'geerec1', 'gde1', 'govwb1', 'govsh41', 'gvxdxe41', 'high65', 'highm65',
'highf65', 'highc65', 'highcm65', 'highcf65', 'human65', 'humanm65',
'humanf65', 'hyr65', 'hyrm65', 'hyrf65', 'no65', 'nom65', 'nof65',
'pinstab1', 'pop65', 'worker65', 'pop1565', 'pop6565', 'sec65',
'secm65', 'secf65', 'secc65', 'seccm65', 'seccf65', 'syr65', 'syrm65',
'syrf65', 'teapri65', 'teasec65', 'ex1', 'im1', 'xr65', 'tot1'],
dtype='object')X.head().T| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Unnamed: 0 | 0.000000 | 1.000000 | 2.000000 | 3.000000 | 4.000000 |
| gdpsh465 | 6.591674 | 6.829794 | 8.895082 | 7.565275 | 7.162397 |
| bmp1l | 0.283700 | 0.614100 | 0.000000 | 0.199700 | 0.174000 |
| freeop | 0.153491 | 0.313509 | 0.204244 | 0.248714 | 0.299252 |
| freetar | 0.043888 | 0.061827 | 0.009186 | 0.036270 | 0.037367 |
| ... | ... | ... | ... | ... | ... |
| teasec65 | 17.300000 | 18.000000 | 20.700000 | 22.700000 | 17.600000 |
| ex1 | 0.072900 | 0.094000 | 0.174100 | 0.126500 | 0.121100 |
| im1 | 0.066700 | 0.143800 | 0.175000 | 0.149600 | 0.130800 |
| xr65 | 0.348000 | 0.525000 | 1.082000 | 6.625000 | 2.500000 |
| tot1 | -0.014727 | 0.005750 | -0.010040 | -0.002195 | 0.003283 |
62 rows × 5 columns
The outcome variable is represented here:
y.plot.hist(bins=90, title='GDP growth')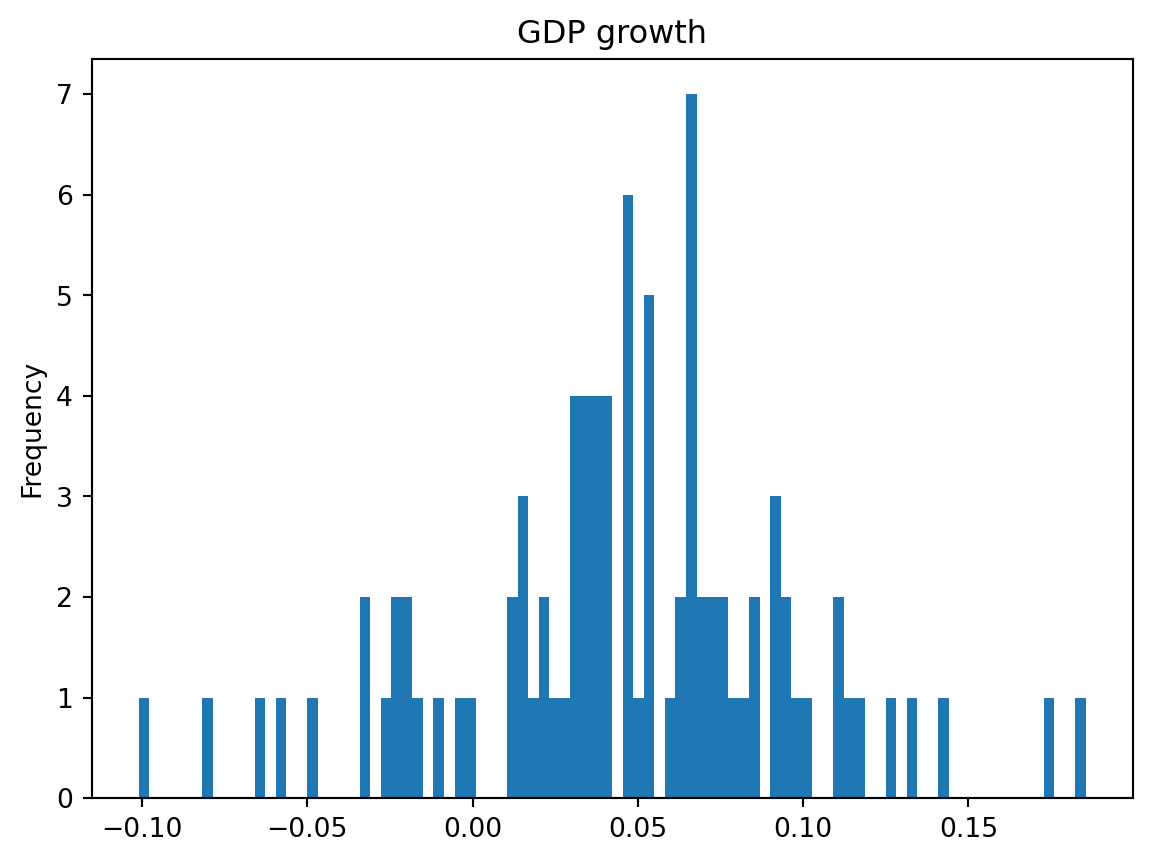
Generally speaking, it is a good idea to establish a benchmark model at the first stages of development of the machine learning model. gingado offers a class of automatic benchmarks that can be used off-the-shelf depending on the task at hand: RegressionBenchmark and ClassificationBenchmark. It is also good to keep in mind that more advanced users can create their own benchmark on top of a base class provided by gingado: ggdBenchmark.
For this application, since we are interested in running a regression task, we will use RegressionBenchmark:
from gingado.benchmark import RegressionBenchmarkWhat this object does is the following:
it creates a random forest
three different versions of the random forest are trained on the user data
the version that performs better is chosen as the benchmark
right after it is trained, the benchmark is documented using gingado’s ModelCard documenter.
The user can easily change the parameters above. For example, instead of a random forest the user might prefer a neural network as the benchmark. Or, in lieu of the default parameters provided by gingado, users might have their own idea of what could be a reasonable parameter space to search.
Random forests are chosen as the go-to benchmark algorithm because of their reasonably good performance in a wide variety of settings, the fact that they don’t require much data transformation (ie, normalising the data to have zero mean and one standard deviation), and by virtue of their relatively transparency about the importance of each regressor.
The first step is to initialise the benchmark object. At this time, we pass some arguments about how we want it to behave. In this case, we set the verbosity level to produce output related to each alternative considered. Then we fit it to the data.
#####
#####
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor()
rfr.fit(X, y)RandomForestRegressor()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
RandomForestRegressor()
benchmark = RegressionBenchmark(verbose_grid=2)
benchmark.fit(X, y)Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4sRegressionBenchmark(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
verbose_grid=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. RegressionBenchmark(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
verbose_grid=2)RandomForestRegressor(oob_score=True)
RandomForestRegressor(oob_score=True)
As we can see above, with a few lines we have trained a random forest on the dataset. In this case, the benchmark was the better of six versions of the random forest, according to the default hyperparameters: 100 and 250 estimators were alternated with models for which the maximum number of regressors analysed by individual trees changesd fom the maximum, a square root and a log of the number of regressors. They were each trained using a 5-fold cross-validation.
Let’s see which one was the best performing in this case, and hence our benchmark model:
pd.DataFrame(benchmark.benchmark.cv_results_).T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| mean_fit_time | 0.084584 | 0.21026 | 0.07873 | 0.195182 | 0.212916 | 0.525036 |
| std_fit_time | 0.001223 | 0.003457 | 0.001558 | 0.001647 | 0.004487 | 0.005444 |
| mean_score_time | 0.003947 | 0.010755 | 0.003852 | 0.010055 | 0.004799 | 0.009249 |
| std_score_time | 0.000343 | 0.001416 | 0.000318 | 0.001067 | 0.000871 | 0.000404 |
| param_max_features | sqrt | sqrt | log2 | log2 | None | None |
| param_n_estimators | 100 | 250 | 100 | 250 | 100 | 250 |
| params | {'max_features': 'sqrt', 'n_estimators': 100} | {'max_features': 'sqrt', 'n_estimators': 250} | {'max_features': 'log2', 'n_estimators': 100} | {'max_features': 'log2', 'n_estimators': 250} | {'max_features': None, 'n_estimators': 100} | {'max_features': None, 'n_estimators': 250} |
| split0_test_score | -0.307724 | -0.295442 | -0.369743 | -0.364862 | -0.704354 | -0.842849 |
| split1_test_score | -0.225049 | -0.280724 | -0.341735 | -0.25398 | -0.430022 | -0.456094 |
| split2_test_score | 0.277885 | 0.058142 | -0.039341 | -0.144171 | 0.113993 | 0.001248 |
| split3_test_score | -0.062042 | 0.024449 | 0.012037 | 0.000738 | 0.107748 | 0.046741 |
| split4_test_score | 0.486432 | 0.352828 | 0.35989 | 0.33426 | 0.54888 | 0.585196 |
| split5_test_score | 0.271536 | 0.222946 | 0.247804 | 0.232893 | 0.274332 | 0.184058 |
| split6_test_score | 0.09285 | 0.146654 | 0.141137 | 0.156117 | -0.087415 | -0.081658 |
| split7_test_score | -0.302397 | -0.275763 | -0.24349 | -0.346615 | -0.384432 | -0.435513 |
| split8_test_score | 0.224493 | 0.316595 | 0.346903 | 0.108168 | 0.519231 | 0.359718 |
| split9_test_score | 0.497676 | 0.44778 | 0.396316 | 0.434762 | 0.552976 | 0.560115 |
| mean_test_score | 0.095366 | 0.071747 | 0.050978 | 0.015731 | 0.051094 | -0.007904 |
| std_test_score | 0.290509 | 0.262884 | 0.278701 | 0.269656 | 0.422714 | 0.439974 |
| rank_test_score | 1 | 2 | 4 | 5 | 3 | 6 |
The values above are calculated with \(R^2\), the default scoring function for a random forest from the scikit-learn package. Suppose that instead we would like a benchmark model that is optimised on the maximum error, ie a benchmark that minimises the worst deviation from prediction to ground truth for all the sample. These are the steps that we would take. Note that a more complete list of ready-made scoring parameters and how to create your own function can be found here.
benchmark_lower_worsterror = RegressionBenchmark(scoring='neg_max_error', verbose_grid=2)
benchmark_lower_worsterror.fit(X, y)Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4sRegressionBenchmark(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
scoring='neg_max_error', verbose_grid=2)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. RegressionBenchmark(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
scoring='neg_max_error', verbose_grid=2)RandomForestRegressor(oob_score=True)
RandomForestRegressor(oob_score=True)
pd.DataFrame(benchmark_lower_worsterror.benchmark.cv_results_).T| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| mean_fit_time | 0.08355 | 0.209482 | 0.079199 | 0.194955 | 0.212919 | 0.527134 |
| std_fit_time | 0.001032 | 0.002904 | 0.001832 | 0.002926 | 0.003435 | 0.004452 |
| mean_score_time | 0.004004 | 0.010152 | 0.004053 | 0.009656 | 0.004299 | 0.009232 |
| std_score_time | 0.000016 | 0.001482 | 0.000347 | 0.000871 | 0.000641 | 0.000422 |
| param_max_features | sqrt | sqrt | log2 | log2 | None | None |
| param_n_estimators | 100 | 250 | 100 | 250 | 100 | 250 |
| params | {'max_features': 'sqrt', 'n_estimators': 100} | {'max_features': 'sqrt', 'n_estimators': 250} | {'max_features': 'log2', 'n_estimators': 100} | {'max_features': 'log2', 'n_estimators': 250} | {'max_features': None, 'n_estimators': 100} | {'max_features': None, 'n_estimators': 250} |
| split0_test_score | -0.12992 | -0.123556 | -0.119944 | -0.129645 | -0.153895 | -0.158485 |
| split1_test_score | -0.086947 | -0.083472 | -0.093789 | -0.082288 | -0.082635 | -0.076733 |
| split2_test_score | -0.090093 | -0.08104 | -0.092357 | -0.085456 | -0.083836 | -0.0956 |
| split3_test_score | -0.138959 | -0.133748 | -0.134143 | -0.129153 | -0.16315 | -0.171333 |
| split4_test_score | -0.128692 | -0.12403 | -0.127822 | -0.125063 | -0.124759 | -0.12912 |
| split5_test_score | -0.116478 | -0.125492 | -0.117873 | -0.122701 | -0.118721 | -0.125288 |
| split6_test_score | -0.090274 | -0.090572 | -0.095279 | -0.101549 | -0.067831 | -0.0726 |
| split7_test_score | -0.086304 | -0.079419 | -0.073502 | -0.083459 | -0.080374 | -0.082562 |
| split8_test_score | -0.0487 | -0.050057 | -0.061613 | -0.050064 | -0.047758 | -0.051066 |
| split9_test_score | -0.08258 | -0.086251 | -0.088288 | -0.082741 | -0.093031 | -0.090251 |
| mean_test_score | -0.099895 | -0.097764 | -0.100461 | -0.099212 | -0.101599 | -0.105304 |
| std_test_score | 0.026445 | 0.025884 | 0.022555 | 0.025414 | 0.035484 | 0.037176 |
| rank_test_score | 3 | 1 | 4 | 2 | 5 | 6 |
Now we even have two benchmark models.
We could further tweak and adjust them, but one of the ideas behind having a benchmark is that it is simple and easy to set up.
Let’s retain only the first benchmark, for simplicity, and now look at the predictions, comparing them to the original growth values.
y_pred = benchmark.predict(X)
pd.DataFrame({
'y': y,
'y_pred': y_pred
}).plot.scatter(
x='y', y='y_pred',
grid=True,
title='Actual and predicted outcome',
xlabel='actual GDP growth',
ylabel='predicted GDP growth')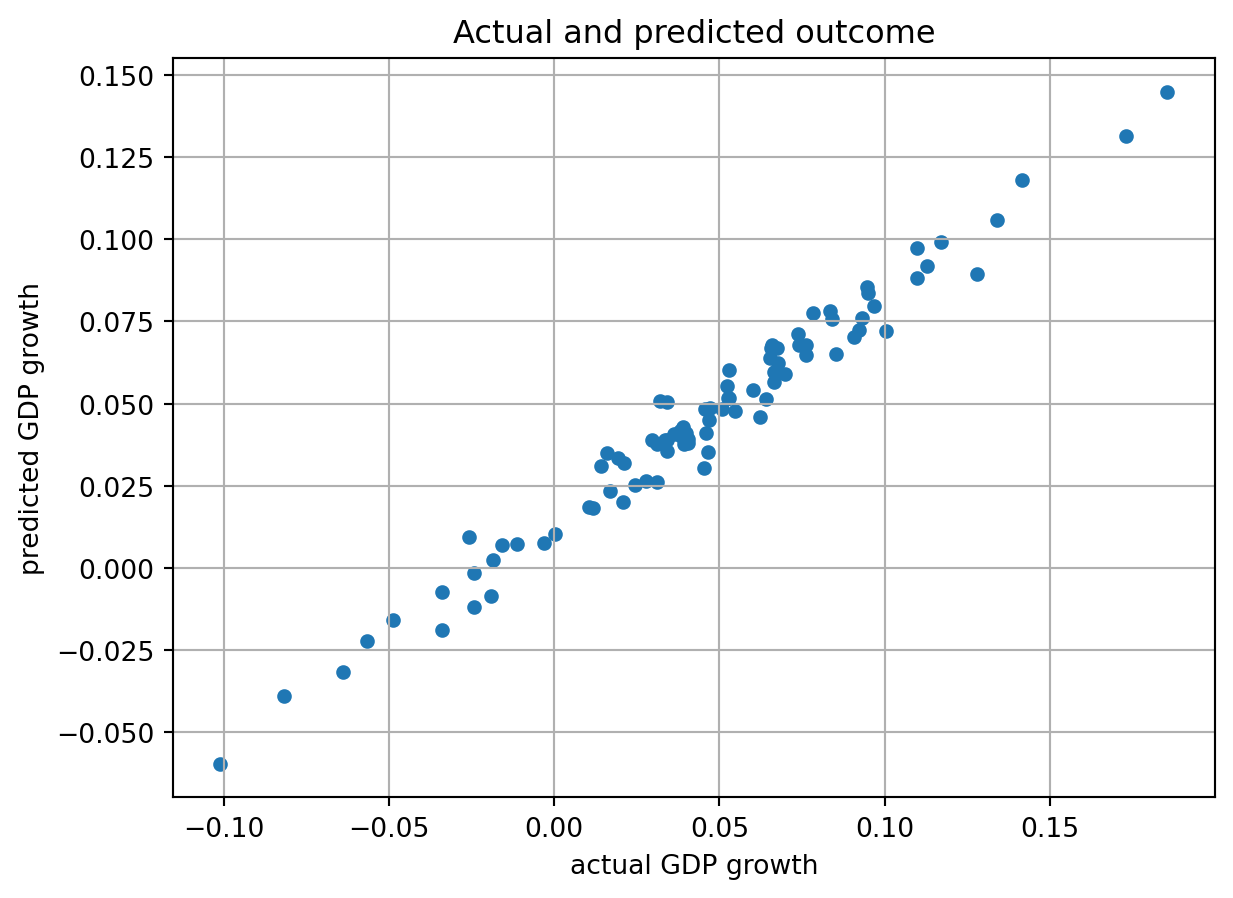
And now a histogram of the benchmark’s errors:
pd.DataFrame(y - y_pred).plot.hist(bins=30, title='Residual')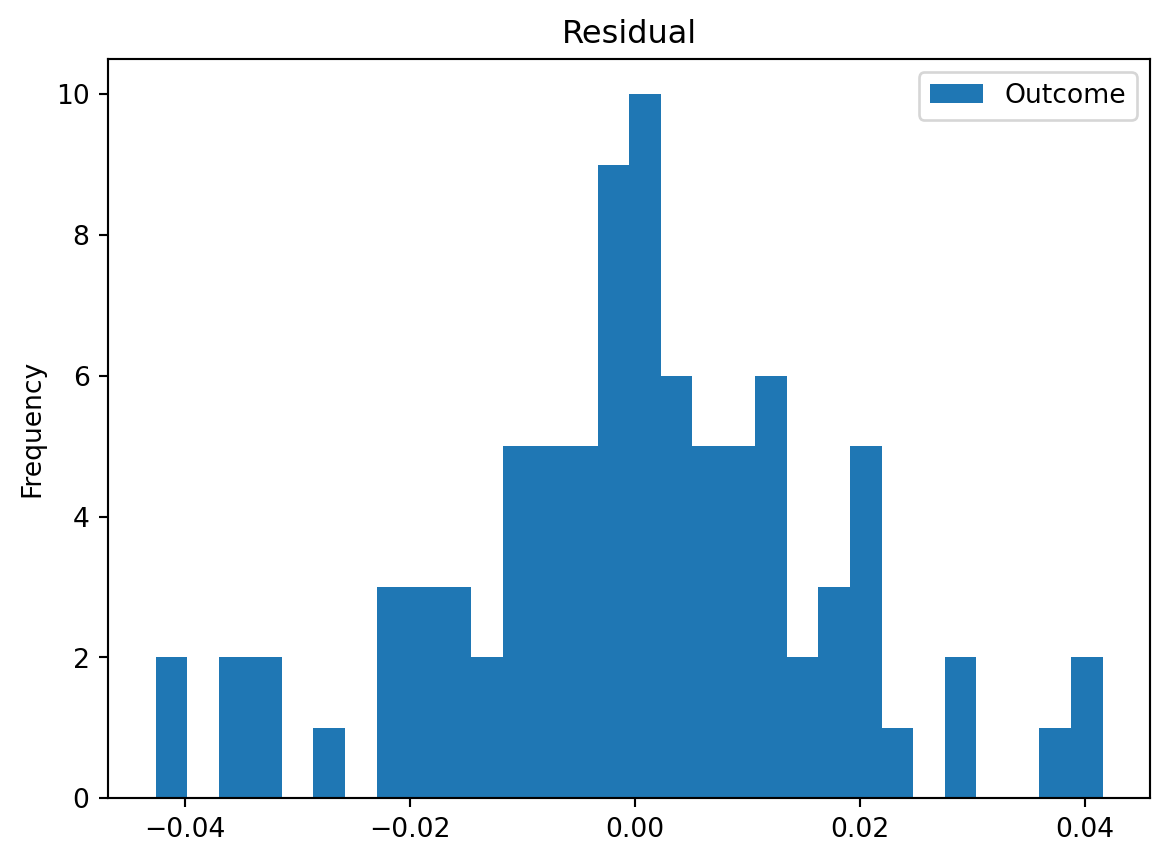
Since the benchmark is a random forest model, we can see what are the most important regressors, measured as the average reduction in impurity across the trees in the random forest that actually use that particular regressor. They are scaled so that the sum for all features is one. Higher importance amounts indicate that that particular regressor is a more important contributor to the final prediction.
regressor_importance = pd.DataFrame(
benchmark.benchmark.best_estimator_.feature_importances_,
index=X.columns,
columns=["Importance"]
)
regressor_importance.sort_values(by="Importance", ascending=False) \
.plot.bar(figsize=(20, 8), title='Regressor importance')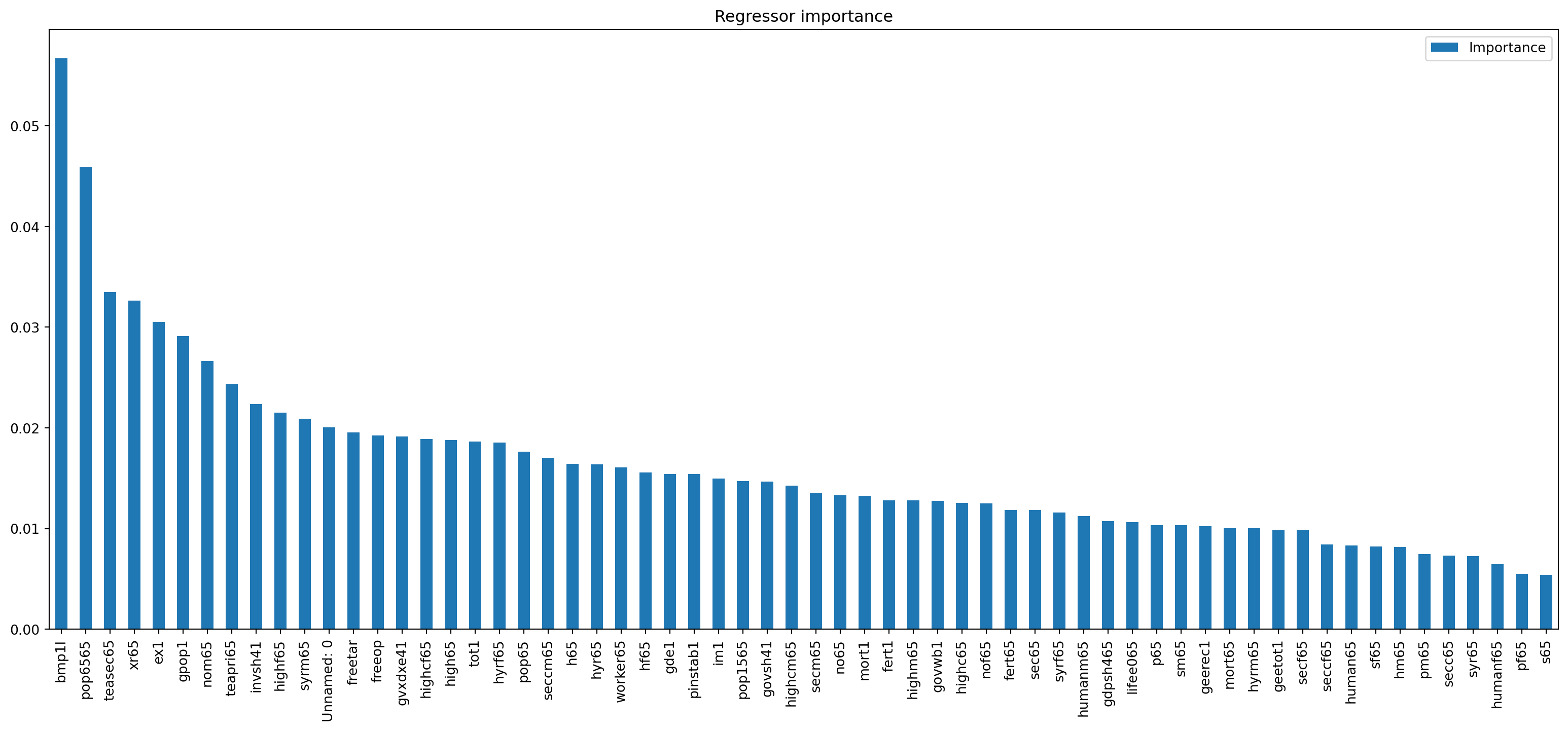
From the graph above, we can see that the regressor bmp1l (black-market premium on foreign exchange) predominates. Interestingly, Belloni, Chernozhukov, and Hansen (2011) using squared-root lasso also find this regressor to be important.
Now we can leverage our automatic benchmark model to test the conditional converge hypothesis - ie, the preposition that countries with lower starting GDP tend to grow faster than other comparable countries. In other words, this hypothesis predicts that when GDP growth is regressed on the level of past GDP and on an adequate set of covariates \(X\), the coefficient on past GDP levels are negative.
Since we have the results for the importance of each regressor in separating countries by their growth result, we can compare the estimated coefficient for GDP levels in regressions that include different regressors in the vector \(X\). To maintain this example a simple exercise, the following three models are estimated:
A result that would be consistent with the conditionality of the conditional convergence hypothesis is the first equation resulting in a negative coefficient for starting GDP, while the following two equations may not necessarily be successful in identifying a negative coefficient. This is because the least important regressors are not likely to have sufficient predictive power to separate countries into comparable groups.
The five more and less important regressors are:
top_five = regressor_importance.sort_values(by="Importance", ascending=False).head(5)
bottom_five = regressor_importance.sort_values(by="Importance", ascending=True).head(5)
top_five, bottom_five( Importance
bmp1l 0.056722
pop6565 0.045948
teasec65 0.033482
xr65 0.032641
ex1 0.030498,
Importance
s65 0.005387
pf65 0.005492
humanf65 0.006471
syr65 0.007239
secc65 0.007303)import statsmodels.api as smgdp_level = 'gdpsh465'X_topfive = X[[gdp_level] + list(top_five.index)]
X_topfive = sm.add_constant(X_topfive)
X_topfive.head()| const | gdpsh465 | bmp1l | pop6565 | teasec65 | xr65 | ex1 | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 6.591674 | 0.2837 | 0.027591 | 17.3 | 0.348 | 0.0729 |
| 1 | 1.0 | 6.829794 | 0.6141 | 0.035637 | 18.0 | 0.525 | 0.0940 |
| 2 | 1.0 | 8.895082 | 0.0000 | 0.076685 | 20.7 | 1.082 | 0.1741 |
| 3 | 1.0 | 7.565275 | 0.1997 | 0.031039 | 22.7 | 6.625 | 0.1265 |
| 4 | 1.0 | 7.162397 | 0.1740 | 0.026281 | 17.6 | 2.500 | 0.1211 |
X_bottomfive = X[[gdp_level] + list(bottom_five.index)]
X_bottomfive = sm.add_constant(X_bottomfive)
X_bottomfive.head()| const | gdpsh465 | s65 | pf65 | humanf65 | syr65 | secc65 | |
|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 6.591674 | 0.04 | 0.21 | 0.043 | 0.033 | 0.13 |
| 1 | 1.0 | 6.829794 | 0.16 | 0.65 | 0.257 | 0.173 | 1.36 |
| 2 | 1.0 | 8.895082 | 0.56 | 1.00 | 8.384 | 2.573 | 15.68 |
| 3 | 1.0 | 7.565275 | 0.24 | 1.00 | 3.807 | 0.438 | 2.76 |
| 4 | 1.0 | 7.162397 | 0.17 | 0.81 | 1.720 | 0.257 | 2.17 |
X_onlyGDPlevel = sm.add_constant(X[gdp_level])
X_onlyGDPlevel.head()| const | gdpsh465 | |
|---|---|---|
| 0 | 1.0 | 6.591674 |
| 1 | 1.0 | 6.829794 |
| 2 | 1.0 | 8.895082 |
| 3 | 1.0 | 7.565275 |
| 4 | 1.0 | 7.162397 |
models = dict(
topfive = sm.OLS(y, X_topfive).fit(),
bottomfive = sm.OLS(y, X_bottomfive).fit(),
onlyGDPlevel = sm.OLS(y, X_onlyGDPlevel).fit()
)coefs = pd.DataFrame({name: model.conf_int().loc[gdp_level] for name, model in models.items()})
coefs.loc[0.5] = [model.params[gdp_level] for _, model in models.items()]
coefs = coefs.sort_index().reset_index(drop=True)
coefs.index = ['[0.025', 'coef on GDP levels', '0.975]']
coefs| topfive | bottomfive | onlyGDPlevel | |
|---|---|---|---|
| [0.025 | -0.038529 | -0.039050 | -0.010810 |
| coef on GDP levels | -0.020704 | -0.014362 | 0.001317 |
| 0.975] | -0.002878 | 0.010326 | 0.013444 |
The equation using the top five regressors in explanatory power yielded a coefficient that is statistically speaking negative under the usual confidence interval levels. In contrast, the regression using the bottom five regressors failed to maintain that level of statistical significance (although the coefficient point estimate was still negative). And finally the regression on GDP level solely resulted, as in the past literature, on a point estimate that is also statistically not different than zero.
These results above offer a different way to add evidence to the conditional convergence hypothesis. In particular, with the help of gingado’s RegressionBenchmark model, it is possible to identify which covariates can meaningfully serve as covariates in a growth equation from those that cannot. This is important because if the covariate selection for some reason included only variables with little explanatory power instead of the most relevant ones, an economist might erroneously reach a different conclusion.
Importantly for model documentation, the benchmark already has some baseline documentation set up. If the user wishes, they can use that as a basis to document their model. Note that the output is in a raw format that is suitable for machine reading and writing. Intermediary and advanced users may wish to use that format to construct personalised forms, documents, etc.
benchmark.model_documentation.show_json(){'model_details': {'developer': 'Person or organisation developing the model',
'datetime': '2025-03-10 15:33:37 ',
'version': 'Model version',
'type': 'Model type',
'info': {'_estimator_type': 'regressor',
'best_estimator_': RandomForestRegressor(max_features='sqrt', oob_score=True),
'best_index_': np.int64(0),
'best_params_': {'max_features': 'sqrt', 'n_estimators': 100},
'best_score_': np.float64(0.09536609382948993),
'cv_results_': {'mean_fit_time': array([0.0845844 , 0.2102602 , 0.07873034, 0.19518211, 0.21291616,
0.52503605]),
'std_fit_time': array([0.00122269, 0.0034574 , 0.0015576 , 0.00164723, 0.00448732,
0.00544404]),
'mean_score_time': array([0.00394657, 0.0107549 , 0.00385215, 0.01005518, 0.00479922,
0.00924947]),
'std_score_time': array([0.00034283, 0.00141606, 0.00031809, 0.0010671 , 0.00087118,
0.00040413]),
'param_max_features': masked_array(data=['sqrt', 'sqrt', 'log2', 'log2', None, None],
mask=[False, False, False, False, False, False],
fill_value=np.str_('?'),
dtype=object),
'param_n_estimators': masked_array(data=[100, 250, 100, 250, 100, 250],
mask=[False, False, False, False, False, False],
fill_value=999999),
'params': [{'max_features': 'sqrt', 'n_estimators': 100},
{'max_features': 'sqrt', 'n_estimators': 250},
{'max_features': 'log2', 'n_estimators': 100},
{'max_features': 'log2', 'n_estimators': 250},
{'max_features': None, 'n_estimators': 100},
{'max_features': None, 'n_estimators': 250}],
'split0_test_score': array([-0.30772411, -0.29544175, -0.36974342, -0.3648617 , -0.70435364,
-0.84284887]),
'split1_test_score': array([-0.22504936, -0.28072364, -0.34173498, -0.25398001, -0.43002179,
-0.45609412]),
'split2_test_score': array([ 0.27788542, 0.05814184, -0.03934118, -0.14417093, 0.11399319,
0.00124754]),
'split3_test_score': array([-0.06204193, 0.02444889, 0.01203693, 0.00073813, 0.10774841,
0.04674113]),
'split4_test_score': array([0.4864325 , 0.35282753, 0.35988962, 0.33425951, 0.54888048,
0.58519599]),
'split5_test_score': array([0.27153583, 0.2229456 , 0.24780389, 0.23289302, 0.2743319 ,
0.1840582 ]),
'split6_test_score': array([ 0.09285003, 0.14665435, 0.14113668, 0.15611662, -0.08741523,
-0.08165759]),
'split7_test_score': array([-0.30239657, -0.27576309, -0.24349019, -0.34661541, -0.38443219,
-0.43551293]),
'split8_test_score': array([0.22449318, 0.31659538, 0.34690332, 0.10816796, 0.51923092,
0.35971792]),
'split9_test_score': array([0.49767595, 0.44778009, 0.39631589, 0.4347619 , 0.55297572,
0.56011505]),
'mean_test_score': array([ 0.09536609, 0.07174652, 0.05097766, 0.01573091, 0.05109378,
-0.00790377]),
'std_test_score': array([0.29050913, 0.26288374, 0.27870072, 0.2696558 , 0.42271402,
0.4399744 ]),
'rank_test_score': array([1, 2, 4, 5, 3, 6], dtype=int32)},
'multimetric_': False,
'n_features_in_': 62,
'n_splits_': 10,
'refit_time_': 0.08451128005981445,
'scorer_': <class 'sklearn.ensemble._forest.RandomForestRegressor'>.score},
'paper': 'Paper or other resource for more information',
'citation': 'Citation details',
'license': 'License',
'contact': 'Where to send questions or comments about the model'},
'intended_use': {'primary_uses': 'Primary intended uses',
'primary_users': 'Primary intended users',
'out_of_scope': 'Out-of-scope use cases'},
'factors': {'relevant': 'Relevant factors',
'evaluation': 'Evaluation factors'},
'metrics': {'performance_measures': 'Model performance measures',
'thresholds': 'Decision thresholds',
'variation_approaches': 'Variation approaches'},
'evaluation_data': {'datasets': 'Datasets',
'motivation': 'Motivation',
'preprocessing': 'Preprocessing'},
'training_data': {'training_data': 'Information on training data'},
'quant_analyses': {'unitary': 'Unitary results',
'intersectional': 'Intersectional results'},
'ethical_considerations': {'sensitive_data': 'Does the model use any sensitive data (e.g., protected classes)?',
'human_life': 'Is the model intended to inform decisions about matters central to human life or flourishing - e.g., health or safety? Or could it be used in such a way?',
'mitigations': 'What risk mitigation strategies were used during model development?',
'risks_and_harms': 'What risks may be present in model usage? Try to identify the potential recipients,likelihood, and magnitude of harms. If these cannot be determined, note that they were considered but remain unknown',
'use_cases': 'Are there any known model use cases that are especially fraught?',
'additional_information': 'If possible, this section should also include any additional ethical considerations that went into model development, for example, review by an external board, or testing with a specific community.'},
'caveats_recommendations': {'caveats': 'For example, did the results suggest any further testing? Were there any relevant groups that were not represented in the evaluation dataset?',
'recommendations': 'Are there additional recommendations for model use? What are the ideal characteristics of an evaluation dataset for this model?'}}Since there is some information in the model documentation that was automatically added, we might want to concentrate on the fields in the model card that are yet to be answered. Actually, this is the purpose of gingado’s automatic documentation: to afford users more time so they can invest, if they want, on model documentation.
benchmark.model_documentation.open_questions()['model_details__developer',
'model_details__version',
'model_details__type',
'model_details__paper',
'model_details__citation',
'model_details__license',
'model_details__contact',
'intended_use__primary_uses',
'intended_use__primary_users',
'intended_use__out_of_scope',
'factors__relevant',
'factors__evaluation',
'metrics__performance_measures',
'metrics__thresholds',
'metrics__variation_approaches',
'evaluation_data__datasets',
'evaluation_data__motivation',
'evaluation_data__preprocessing',
'training_data__training_data',
'quant_analyses__unitary',
'quant_analyses__intersectional',
'ethical_considerations__sensitive_data',
'ethical_considerations__human_life',
'ethical_considerations__mitigations',
'ethical_considerations__risks_and_harms',
'ethical_considerations__use_cases',
'ethical_considerations__additional_information',
'caveats_recommendations__caveats',
'caveats_recommendations__recommendations']Let’s fill some information:
benchmark.model_documentation.fill_info({
'intended_use': {
'primary_uses': 'This model is trained for pedagogical uses only.',
'primary_users': 'Everyone is welcome to follow the description showing the development of this benchmark.'
}
})Note the format, based on a Python dictionary. In particular, the open_questions method results include keys divided by double underscores. As seen above, these should be interpreted as different levels of the documentation template, leading to a nested dictionary.
Now when we confirm that the questions answered above are no longer “open questions”:
benchmark.model_documentation.open_questions()['model_details__developer',
'model_details__version',
'model_details__type',
'model_details__paper',
'model_details__citation',
'model_details__license',
'model_details__contact',
'intended_use__out_of_scope',
'factors__relevant',
'factors__evaluation',
'metrics__performance_measures',
'metrics__thresholds',
'metrics__variation_approaches',
'evaluation_data__datasets',
'evaluation_data__motivation',
'evaluation_data__preprocessing',
'training_data__training_data',
'quant_analyses__unitary',
'quant_analyses__intersectional',
'ethical_considerations__sensitive_data',
'ethical_considerations__human_life',
'ethical_considerations__mitigations',
'ethical_considerations__risks_and_harms',
'ethical_considerations__use_cases',
'ethical_considerations__additional_information',
'caveats_recommendations__caveats',
'caveats_recommendations__recommendations']If we want, at any time we can save the documentation to a local JSON file, as well as read another document.
The benchmark model may be enough for some analyses, or maybe the user is interested in using the benchmark to explore the data and have an understanding of the importance of each regressor, to concentrate their work on data that can be meaningful for their purposes. But oftentimes a user will want to seek a machine learning model that performs as well as possible.
For users that want to manually create other models, gingado allows the possibility of comparing them with the benchmark. If the user model is better, it becomes the new benchmark!
For the following analyses, we will use K-fold as cross-validation, with 5 splits of the sample.
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import GradientBoostingRegressorparam_grid = {
'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]
}
reg_gradbooster = GradientBoostingRegressor()
gradboosterg_grid = GridSearchCV(
reg_gradbooster,
param_grid,
n_jobs=-1,
verbose=2
).fit(X, y)Fitting 5 folds for each of 9 candidates, totalling 45 fitsy_pred = gradboosterg_grid.predict(X)
pd.DataFrame({
'y': y,
'y_pred': y_pred
}).plot.scatter(x='y', y='y_pred', grid=True)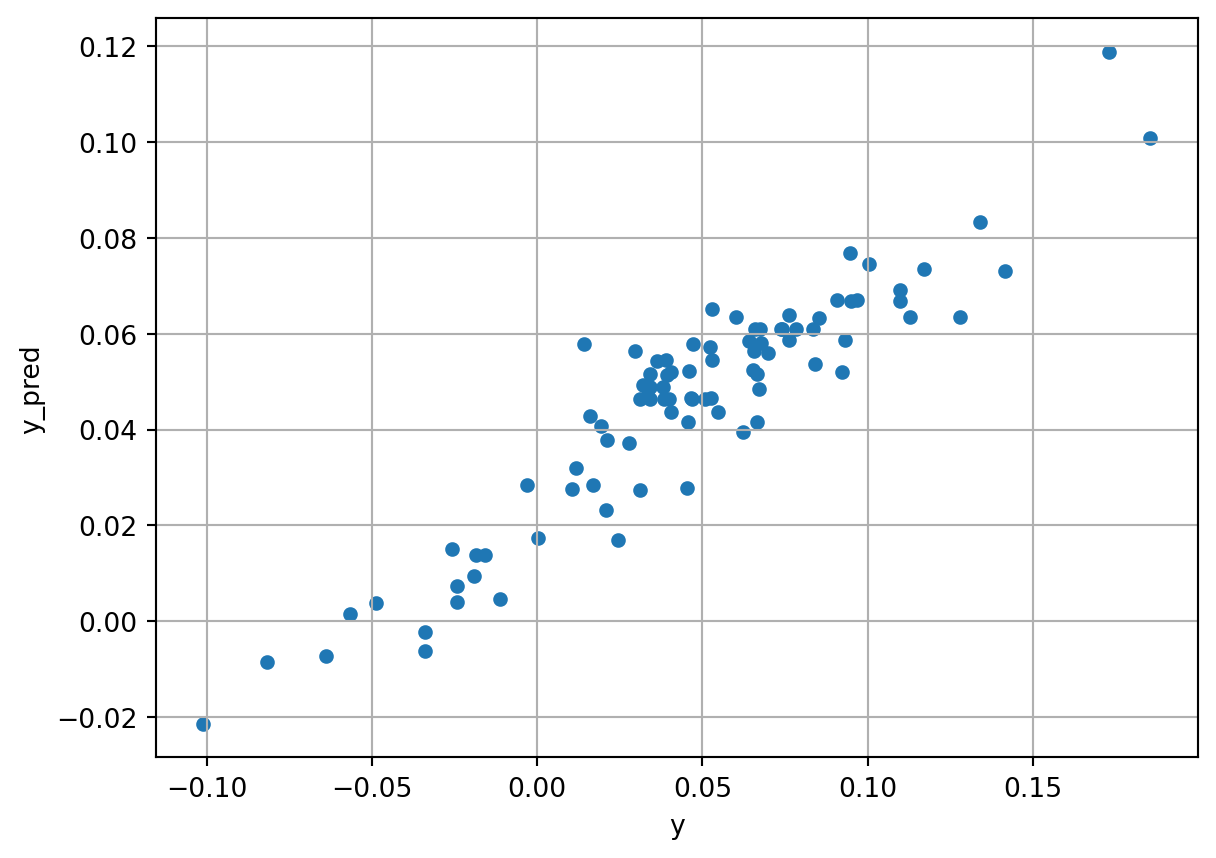
pd.DataFrame(y - y_pred).plot.hist(bins=30)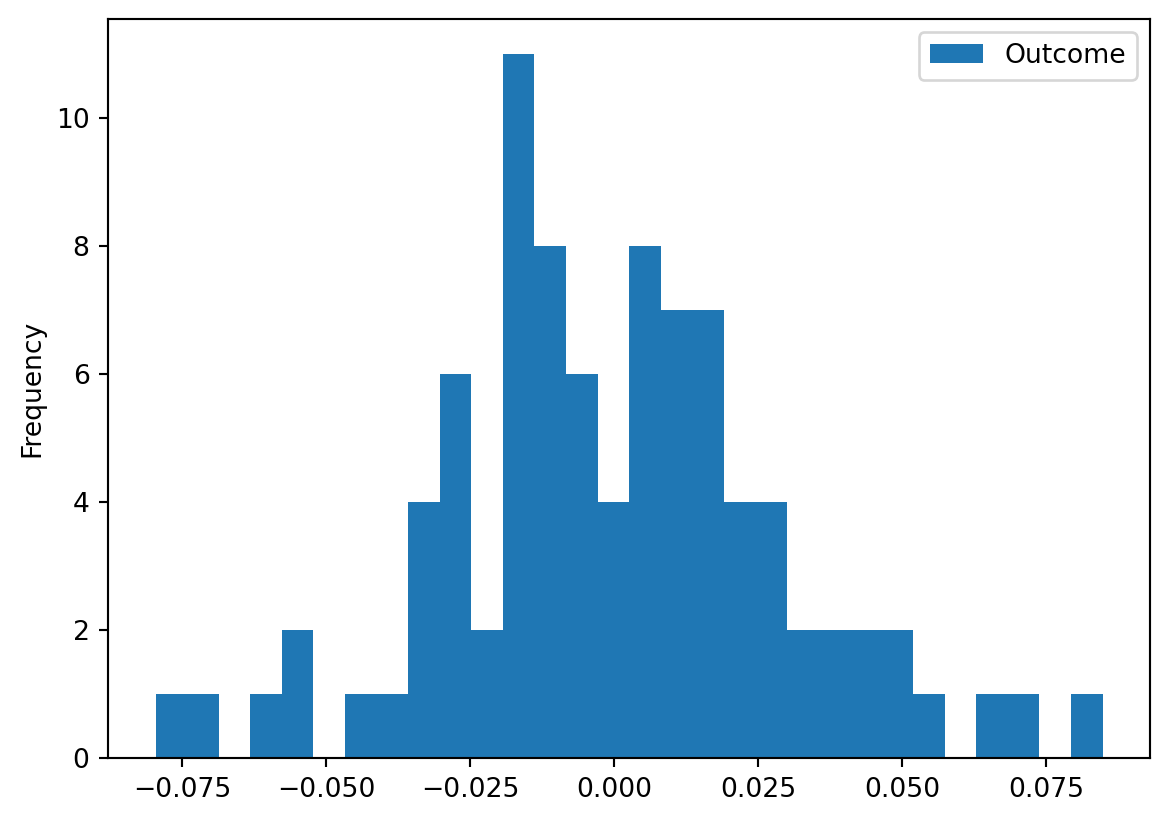
from sklearn.linear_model import Lassoparam_grid = {
'alpha': [0.5, 1, 1.25],
}
reg_lasso = Lasso(fit_intercept=True)
lasso_grid = GridSearchCV(
reg_lasso,
param_grid,
n_jobs=-1,
verbose=2
).fit(X, y)Fitting 5 folds for each of 3 candidates, totalling 15 fitsy_pred = lasso_grid.predict(X)
pd.DataFrame({
'y': y,
'y_pred': y_pred
}).plot.scatter(x='y', y='y_pred', grid=True)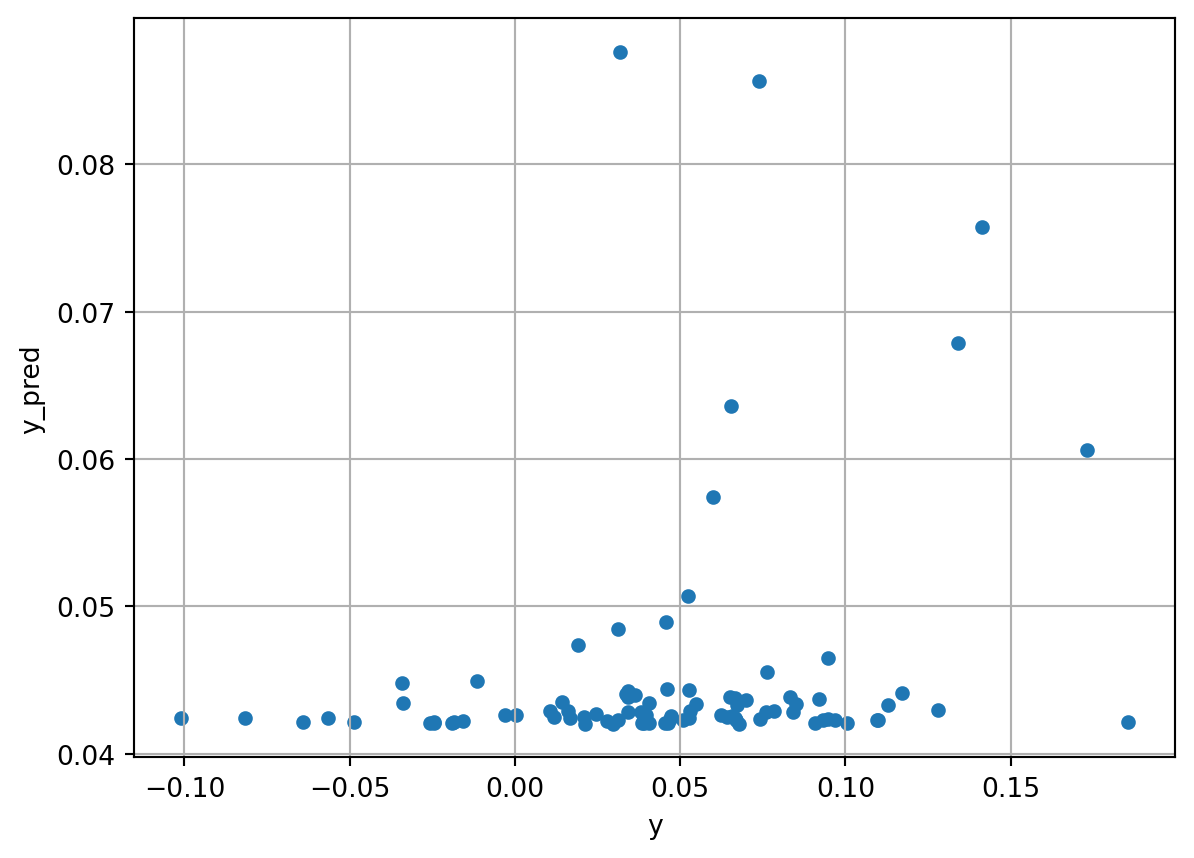
pd.DataFrame(y - y_pred).plot.hist(bins=30)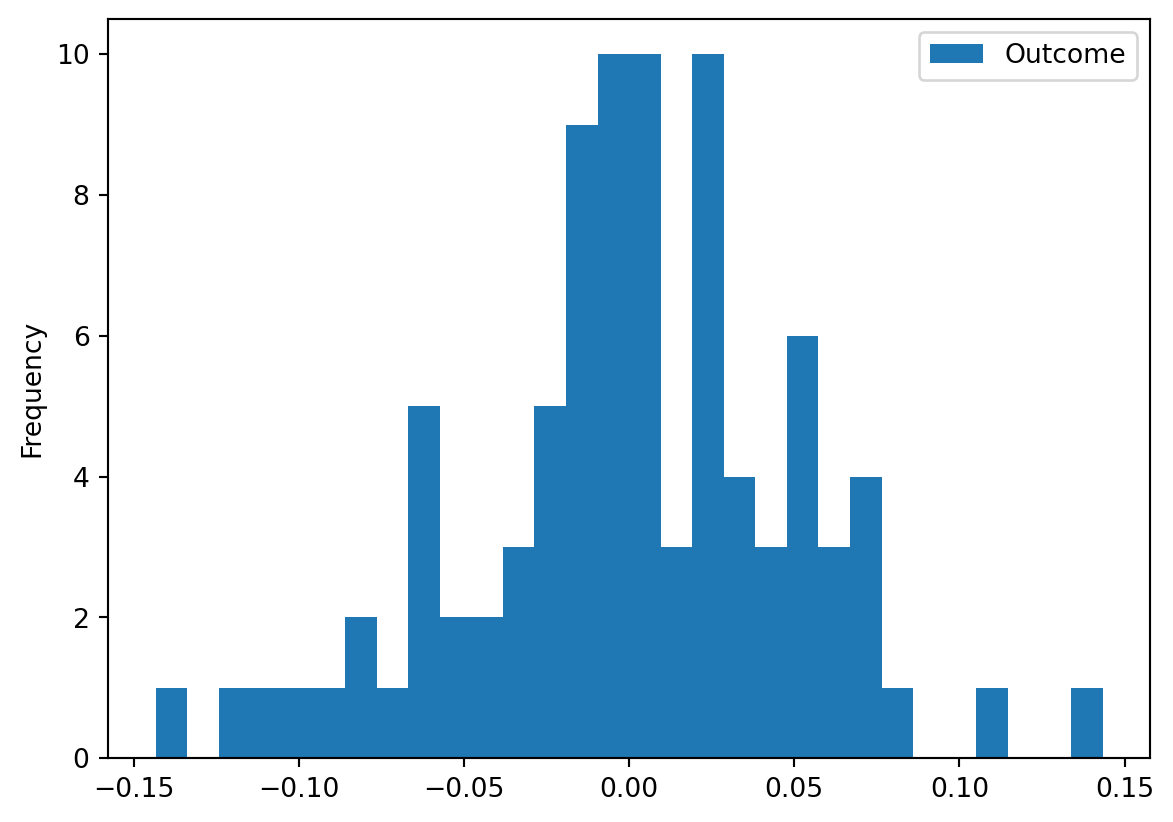
gingado allows users to compare different candidate models with the existing benchmark in a very simple way: using the compare method.
candidates = [gradboosterg_grid, lasso_grid]
benchmark.compare(X, y, candidates)Fitting 10 folds for each of 4 candidates, totalling 40 fits
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 12.8s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 12.7s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.1s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 12.8s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.0s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.2s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.2s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.1s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.2s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.0s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END candidate_estimator=GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2), candidate_estimator__cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None), candidate_estimator__error_score=nan, candidate_estimator__estimator=RandomForestRegressor(oob_score=True), candidate_estimator__estimator__bootstrap=True, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=squared_error, candidate_estimator__estimator__max_depth=None, candidate_estimator__estimator__max_features=1.0, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__max_samples=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__monotonic_cst=None, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_jobs=None, candidate_estimator__estimator__oob_score=True, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=None, candidate_estimator__param_grid={'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 13.5s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.0s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.0s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.0s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.2s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
[CV] END candidate_estimator=GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=GradientBoostingRegressor(), candidate_estimator__estimator__alpha=0.9, candidate_estimator__estimator__ccp_alpha=0.0, candidate_estimator__estimator__criterion=friedman_mse, candidate_estimator__estimator__init=None, candidate_estimator__estimator__learning_rate=0.1, candidate_estimator__estimator__loss=squared_error, candidate_estimator__estimator__max_depth=3, candidate_estimator__estimator__max_features=None, candidate_estimator__estimator__max_leaf_nodes=None, candidate_estimator__estimator__min_impurity_decrease=0.0, candidate_estimator__estimator__min_samples_leaf=1, candidate_estimator__estimator__min_samples_split=2, candidate_estimator__estimator__min_weight_fraction_leaf=0.0, candidate_estimator__estimator__n_estimators=100, candidate_estimator__estimator__n_iter_no_change=None, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__subsample=1.0, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__validation_fraction=0.1, candidate_estimator__estimator__verbose=0, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 1.1s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2), candidate_estimator__cv=None, candidate_estimator__error_score=nan, candidate_estimator__estimator=Lasso(), candidate_estimator__estimator__alpha=1.0, candidate_estimator__estimator__copy_X=True, candidate_estimator__estimator__fit_intercept=True, candidate_estimator__estimator__max_iter=1000, candidate_estimator__estimator__positive=False, candidate_estimator__estimator__precompute=False, candidate_estimator__estimator__random_state=None, candidate_estimator__estimator__selection=cyclic, candidate_estimator__estimator__tol=0.0001, candidate_estimator__estimator__warm_start=False, candidate_estimator__n_jobs=-1, candidate_estimator__param_grid={'alpha': [0.5, 1, 1.25]}, candidate_estimator__pre_dispatch=2*n_jobs, candidate_estimator__refit=True, candidate_estimator__return_train_score=False, candidate_estimator__scoring=None, candidate_estimator__verbose=2; total time= 0.0s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.6s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.1s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.2s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.2s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.4s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 15.0s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 15.0s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.2s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.9s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.9s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 14.6s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Fitting 5 folds for each of 9 candidates, totalling 45 fits
Fitting 5 folds for each of 3 candidates, totalling 15 fits
[CV] END candidate_estimator=VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]); total time= 15.2s
Fitting 10 folds for each of 6 candidates, totalling 60 fits
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=100; total time= 0.0s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=sqrt, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=100; total time= 0.0s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=log2, n_estimators=250; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=100; total time= 0.1s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
[CV] END ................max_features=None, n_estimators=250; total time= 0.5s
[CV] END ................max_features=None, n_estimators=250; total time= 0.4s
Benchmark updated!
New benchmark:
Pipeline(steps=[('candidate_estimator',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2',
None],
'n_estimators': [100, 250]},
verbose=2))])The output above clearly indicates that after evaluating the models - and their ensemble together with the existing benchmark - at least one of them was better than the current benchmark. Therefore, it will now be the new benchmark.
y_pred = benchmark.predict(X)
pd.DataFrame({
'y': y,
'y_pred': y_pred
}).plot.scatter(x='y', y='y_pred', grid=True)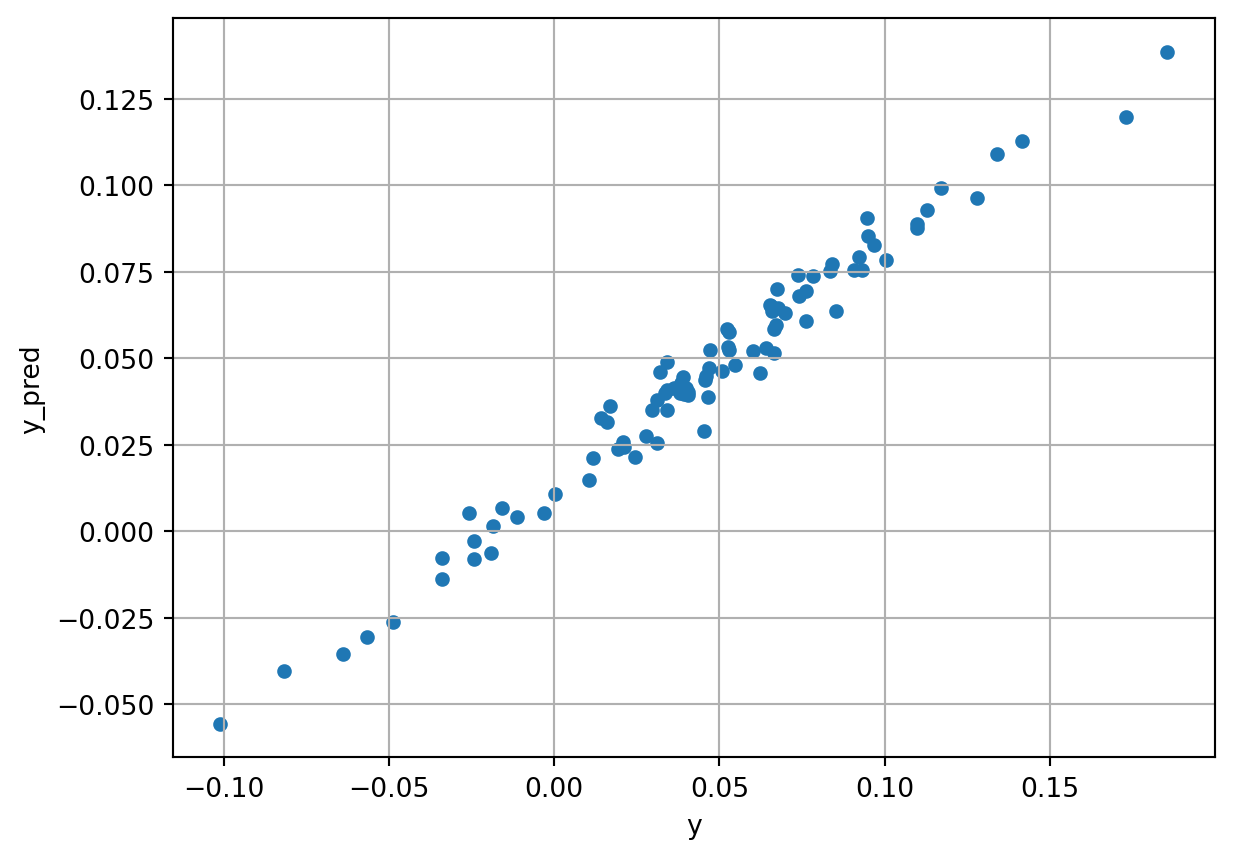
pd.DataFrame(y - y_pred).plot.hist(bins=30)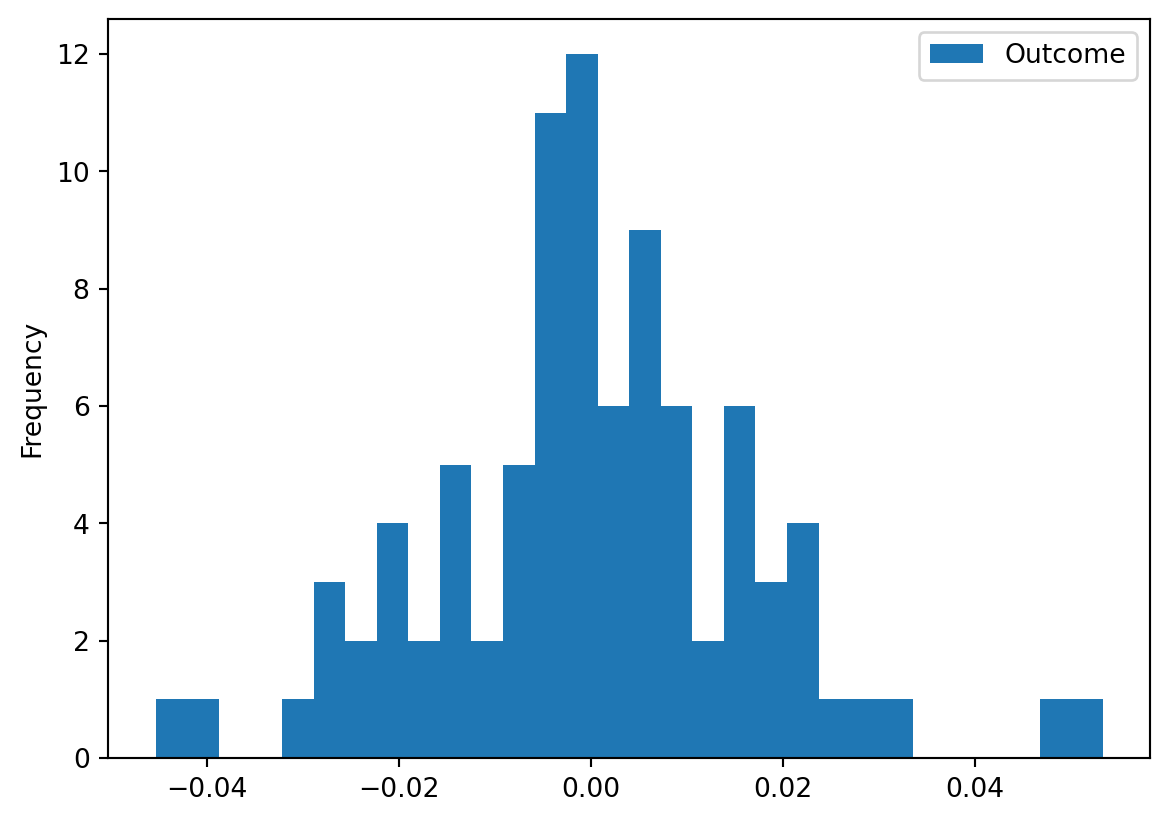
After this process, we can now see how the model documentation was updated automatically:
benchmark.model_documentation.show_json(){'model_details': {'developer': 'Person or organisation developing the model',
'datetime': '2025-03-10 15:39:01 ',
'version': 'Model version',
'type': 'Model type',
'info': {'_estimator_type': 'regressor',
'best_estimator_': Pipeline(steps=[('candidate_estimator',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2',
None],
'n_estimators': [100, 250]},
verbose=2))]),
'best_index_': np.int64(0),
'best_params_': {'candidate_estimator': GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2),
'candidate_estimator__cv': ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
'candidate_estimator__error_score': nan,
'candidate_estimator__estimator': RandomForestRegressor(oob_score=True),
'candidate_estimator__estimator__bootstrap': True,
'candidate_estimator__estimator__ccp_alpha': 0.0,
'candidate_estimator__estimator__criterion': 'squared_error',
'candidate_estimator__estimator__max_depth': None,
'candidate_estimator__estimator__max_features': 1.0,
'candidate_estimator__estimator__max_leaf_nodes': None,
'candidate_estimator__estimator__max_samples': None,
'candidate_estimator__estimator__min_impurity_decrease': 0.0,
'candidate_estimator__estimator__min_samples_leaf': 1,
'candidate_estimator__estimator__min_samples_split': 2,
'candidate_estimator__estimator__min_weight_fraction_leaf': 0.0,
'candidate_estimator__estimator__monotonic_cst': None,
'candidate_estimator__estimator__n_estimators': 100,
'candidate_estimator__estimator__n_jobs': None,
'candidate_estimator__estimator__oob_score': True,
'candidate_estimator__estimator__random_state': None,
'candidate_estimator__estimator__verbose': 0,
'candidate_estimator__estimator__warm_start': False,
'candidate_estimator__n_jobs': None,
'candidate_estimator__param_grid': {'n_estimators': [100, 250],
'max_features': ['sqrt', 'log2', None]},
'candidate_estimator__pre_dispatch': '2*n_jobs',
'candidate_estimator__refit': True,
'candidate_estimator__return_train_score': False,
'candidate_estimator__scoring': None,
'candidate_estimator__verbose': 2},
'best_score_': np.float64(-0.054142646503088386),
'cv_results_': {'mean_fit_time': array([13.13983359, 1.16708853, 0.02613635, 14.78377473]),
'std_fit_time': array([0.2200771 , 0.04360571, 0.00110872, 0.35774527]),
'mean_score_time': array([0.00915532, 0.00160038, 0.00119898, 0.00956423]),
'std_score_time': array([0.0030879 , 0.00049076, 0.0003977 , 0.00274218]),
'param_candidate_estimator': masked_array(data=[GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2) ,
GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2) ,
GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2) ,
VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))]) ],
mask=[False, False, False, False],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__cv': masked_array(data=[ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
None, None, --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__error_score': masked_array(data=[nan, nan, nan, --],
mask=[False, False, False, True],
fill_value=1e+20),
'param_candidate_estimator__estimator': masked_array(data=[RandomForestRegressor(oob_score=True),
GradientBoostingRegressor(), Lasso(), --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__bootstrap': masked_array(data=[True, --, --, --],
mask=[False, True, True, True],
fill_value=True),
'param_candidate_estimator__estimator__ccp_alpha': masked_array(data=[0.0, 0.0, --, --],
mask=[False, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__criterion': masked_array(data=['squared_error', 'friedman_mse', --, --],
mask=[False, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__max_depth': masked_array(data=[None, 3, --, --],
mask=[False, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__max_features': masked_array(data=[1.0, None, --, --],
mask=[False, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__max_leaf_nodes': masked_array(data=[None, None, --, --],
mask=[False, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__max_samples': masked_array(data=[None, --, --, --],
mask=[False, True, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__min_impurity_decrease': masked_array(data=[0.0, 0.0, --, --],
mask=[False, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__min_samples_leaf': masked_array(data=[1, 1, --, --],
mask=[False, False, True, True],
fill_value=999999),
'param_candidate_estimator__estimator__min_samples_split': masked_array(data=[2, 2, --, --],
mask=[False, False, True, True],
fill_value=999999),
'param_candidate_estimator__estimator__min_weight_fraction_leaf': masked_array(data=[0.0, 0.0, --, --],
mask=[False, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__monotonic_cst': masked_array(data=[None, --, --, --],
mask=[False, True, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__n_estimators': masked_array(data=[100, 100, --, --],
mask=[False, False, True, True],
fill_value=999999),
'param_candidate_estimator__estimator__n_jobs': masked_array(data=[None, --, --, --],
mask=[False, True, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__oob_score': masked_array(data=[True, --, --, --],
mask=[False, True, True, True],
fill_value=True),
'param_candidate_estimator__estimator__random_state': masked_array(data=[None, None, None, --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__verbose': masked_array(data=[0, 0, --, --],
mask=[False, False, True, True],
fill_value=999999),
'param_candidate_estimator__estimator__warm_start': masked_array(data=[False, False, False, --],
mask=[False, False, False, True],
fill_value=True),
'param_candidate_estimator__n_jobs': masked_array(data=[None, -1, -1, --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__param_grid': masked_array(data=[{'n_estimators': [100, 250], 'max_features': ['sqrt', 'log2', None]},
{'learning_rate': [0.01, 0.1, 0.25], 'max_depth': [3, 6, 9]},
{'alpha': [0.5, 1, 1.25]}, --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__pre_dispatch': masked_array(data=['2*n_jobs', '2*n_jobs', '2*n_jobs', --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__refit': masked_array(data=[True, True, True, --],
mask=[False, False, False, True],
fill_value=True),
'param_candidate_estimator__return_train_score': masked_array(data=[False, False, False, --],
mask=[False, False, False, True],
fill_value=True),
'param_candidate_estimator__scoring': masked_array(data=[None, None, None, --],
mask=[False, False, False, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__verbose': masked_array(data=[2, 2, 2, --],
mask=[False, False, False, True],
fill_value=999999),
'param_candidate_estimator__estimator__alpha': masked_array(data=[--, 0.9, 1.0, --],
mask=[ True, False, False, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__init': masked_array(data=[--, None, --, --],
mask=[ True, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__learning_rate': masked_array(data=[--, 0.1, --, --],
mask=[ True, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__loss': masked_array(data=[--, 'squared_error', --, --],
mask=[ True, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__n_iter_no_change': masked_array(data=[--, None, --, --],
mask=[ True, False, True, True],
fill_value=np.str_('?'),
dtype=object),
'param_candidate_estimator__estimator__subsample': masked_array(data=[--, 1.0, --, --],
mask=[ True, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__tol': masked_array(data=[--, 0.0001, 0.0001, --],
mask=[ True, False, False, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__validation_fraction': masked_array(data=[--, 0.1, --, --],
mask=[ True, False, True, True],
fill_value=1e+20),
'param_candidate_estimator__estimator__copy_X': masked_array(data=[--, --, True, --],
mask=[ True, True, False, True],
fill_value=True),
'param_candidate_estimator__estimator__fit_intercept': masked_array(data=[--, --, True, --],
mask=[ True, True, False, True],
fill_value=True),
'param_candidate_estimator__estimator__max_iter': masked_array(data=[--, --, 1000, --],
mask=[ True, True, False, True],
fill_value=999999),
'param_candidate_estimator__estimator__positive': masked_array(data=[--, --, False, --],
mask=[ True, True, False, True],
fill_value=True),
'param_candidate_estimator__estimator__precompute': masked_array(data=[--, --, False, --],
mask=[ True, True, False, True],
fill_value=True),
'param_candidate_estimator__estimator__selection': masked_array(data=[--, --, 'cyclic', --],
mask=[ True, True, False, True],
fill_value=np.str_('?'),
dtype=object),
'params': [{'candidate_estimator': GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt', 'log2', None],
'n_estimators': [100, 250]},
verbose=2),
'candidate_estimator__cv': ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
'candidate_estimator__error_score': nan,
'candidate_estimator__estimator': RandomForestRegressor(oob_score=True),
'candidate_estimator__estimator__bootstrap': True,
'candidate_estimator__estimator__ccp_alpha': 0.0,
'candidate_estimator__estimator__criterion': 'squared_error',
'candidate_estimator__estimator__max_depth': None,
'candidate_estimator__estimator__max_features': 1.0,
'candidate_estimator__estimator__max_leaf_nodes': None,
'candidate_estimator__estimator__max_samples': None,
'candidate_estimator__estimator__min_impurity_decrease': 0.0,
'candidate_estimator__estimator__min_samples_leaf': 1,
'candidate_estimator__estimator__min_samples_split': 2,
'candidate_estimator__estimator__min_weight_fraction_leaf': 0.0,
'candidate_estimator__estimator__monotonic_cst': None,
'candidate_estimator__estimator__n_estimators': 100,
'candidate_estimator__estimator__n_jobs': None,
'candidate_estimator__estimator__oob_score': True,
'candidate_estimator__estimator__random_state': None,
'candidate_estimator__estimator__verbose': 0,
'candidate_estimator__estimator__warm_start': False,
'candidate_estimator__n_jobs': None,
'candidate_estimator__param_grid': {'n_estimators': [100, 250],
'max_features': ['sqrt', 'log2', None]},
'candidate_estimator__pre_dispatch': '2*n_jobs',
'candidate_estimator__refit': True,
'candidate_estimator__return_train_score': False,
'candidate_estimator__scoring': None,
'candidate_estimator__verbose': 2},
{'candidate_estimator': GridSearchCV(estimator=GradientBoostingRegressor(), n_jobs=-1,
param_grid={'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
verbose=2),
'candidate_estimator__cv': None,
'candidate_estimator__error_score': nan,
'candidate_estimator__estimator': GradientBoostingRegressor(),
'candidate_estimator__estimator__alpha': 0.9,
'candidate_estimator__estimator__ccp_alpha': 0.0,
'candidate_estimator__estimator__criterion': 'friedman_mse',
'candidate_estimator__estimator__init': None,
'candidate_estimator__estimator__learning_rate': 0.1,
'candidate_estimator__estimator__loss': 'squared_error',
'candidate_estimator__estimator__max_depth': 3,
'candidate_estimator__estimator__max_features': None,
'candidate_estimator__estimator__max_leaf_nodes': None,
'candidate_estimator__estimator__min_impurity_decrease': 0.0,
'candidate_estimator__estimator__min_samples_leaf': 1,
'candidate_estimator__estimator__min_samples_split': 2,
'candidate_estimator__estimator__min_weight_fraction_leaf': 0.0,
'candidate_estimator__estimator__n_estimators': 100,
'candidate_estimator__estimator__n_iter_no_change': None,
'candidate_estimator__estimator__random_state': None,
'candidate_estimator__estimator__subsample': 1.0,
'candidate_estimator__estimator__tol': 0.0001,
'candidate_estimator__estimator__validation_fraction': 0.1,
'candidate_estimator__estimator__verbose': 0,
'candidate_estimator__estimator__warm_start': False,
'candidate_estimator__n_jobs': -1,
'candidate_estimator__param_grid': {'learning_rate': [0.01, 0.1, 0.25],
'max_depth': [3, 6, 9]},
'candidate_estimator__pre_dispatch': '2*n_jobs',
'candidate_estimator__refit': True,
'candidate_estimator__return_train_score': False,
'candidate_estimator__scoring': None,
'candidate_estimator__verbose': 2},
{'candidate_estimator': GridSearchCV(estimator=Lasso(), n_jobs=-1, param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2),
'candidate_estimator__cv': None,
'candidate_estimator__error_score': nan,
'candidate_estimator__estimator': Lasso(),
'candidate_estimator__estimator__alpha': 1.0,
'candidate_estimator__estimator__copy_X': True,
'candidate_estimator__estimator__fit_intercept': True,
'candidate_estimator__estimator__max_iter': 1000,
'candidate_estimator__estimator__positive': False,
'candidate_estimator__estimator__precompute': False,
'candidate_estimator__estimator__random_state': None,
'candidate_estimator__estimator__selection': 'cyclic',
'candidate_estimator__estimator__tol': 0.0001,
'candidate_estimator__estimator__warm_start': False,
'candidate_estimator__n_jobs': -1,
'candidate_estimator__param_grid': {'alpha': [0.5, 1, 1.25]},
'candidate_estimator__pre_dispatch': '2*n_jobs',
'candidate_estimator__refit': True,
'candidate_estimator__return_train_score': False,
'candidate_estimator__scoring': None,
'candidate_estimator__verbose': 2},
{'candidate_estimator': VotingRegressor(estimators=[('candidate_1',
GridSearchCV(cv=ShuffleSplit(n_splits=10, random_state=None, test_size=None, train_size=None),
estimator=RandomForestRegressor(oob_score=True),
param_grid={'max_features': ['sqrt',
'log2',
None],
'n_estimators': [100,
250]},
verbose=2)),
('candidate_2',
GridSearchCV(estimator=GradientBoostingRegressor(),
n_jobs=-1,
param_grid={'learning_rate': [0.01,
0.1,
0.25],
'max_depth': [3, 6, 9]},
verbose=2)),
('candidate_3',
GridSearchCV(estimator=Lasso(), n_jobs=-1,
param_grid={'alpha': [0.5, 1, 1.25]},
verbose=2))])}],
'split0_test_score': array([ 0.5201971 , 0.37166145, -0.04995436, 0.33727544]),
'split1_test_score': array([-1.31031808, -0.95267566, -1.61475036, -1.22050682]),
'split2_test_score': array([-0.03379594, -0.09305321, 0.07406248, 0.00641247]),
'split3_test_score': array([-0.46344952, -0.46943705, -0.94693155, -0.58344125]),
'split4_test_score': array([-0.75237914, -0.63351526, -0.9657156 , -0.71569447]),
'split5_test_score': array([ 0.3564945 , -0.2872439 , 0.03223702, 0.31517031]),
'split6_test_score': array([ 0.15826869, 0.14798779, -0.0232804 , 0.19024978]),
'split7_test_score': array([ 0.24779457, 0.23423802, -0.09430567, 0.16062537]),
'split8_test_score': array([ 0.51647376, 0.07678925, -0.03596349, 0.52558861]),
'split9_test_score': array([ 0.21928761, 0.03628117, -0.01417034, 0.09509182]),
'mean_test_score': array([-0.05414265, -0.15689674, -0.36387723, -0.08892288]),
'std_test_score': array([0.57171653, 0.39955209, 0.55969527, 0.53137519]),
'rank_test_score': array([1, 3, 4, 2], dtype=int32)},
'feature_names_in_': array(['Unnamed: 0', 'gdpsh465', 'bmp1l', 'freeop', 'freetar', 'h65',
'hm65', 'hf65', 'p65', 'pm65', 'pf65', 's65', 'sm65', 'sf65',
'fert65', 'mort65', 'lifee065', 'gpop1', 'fert1', 'mort1',
'invsh41', 'geetot1', 'geerec1', 'gde1', 'govwb1', 'govsh41',
'gvxdxe41', 'high65', 'highm65', 'highf65', 'highc65', 'highcm65',
'highcf65', 'human65', 'humanm65', 'humanf65', 'hyr65', 'hyrm65',
'hyrf65', 'no65', 'nom65', 'nof65', 'pinstab1', 'pop65',
'worker65', 'pop1565', 'pop6565', 'sec65', 'secm65', 'secf65',
'secc65', 'seccm65', 'seccf65', 'syr65', 'syrm65', 'syrf65',
'teapri65', 'teasec65', 'ex1', 'im1', 'xr65', 'tot1'], dtype=object),
'multimetric_': False,
'n_features_in_': 62,
'n_splits_': 10,
'refit_time_': 14.294554233551025,
'scorer_': <class 'sklearn.pipeline.Pipeline'>.score},
'paper': 'Paper or other resource for more information',
'citation': 'Citation details',
'license': 'License',
'contact': 'Where to send questions or comments about the model'},
'intended_use': {'primary_uses': 'Primary intended uses',
'primary_users': 'Primary intended users',
'out_of_scope': 'Out-of-scope use cases'},
'factors': {'relevant': 'Relevant factors',
'evaluation': 'Evaluation factors'},
'metrics': {'performance_measures': 'Model performance measures',
'thresholds': 'Decision thresholds',
'variation_approaches': 'Variation approaches'},
'evaluation_data': {'datasets': 'Datasets',
'motivation': 'Motivation',
'preprocessing': 'Preprocessing'},
'training_data': {'training_data': 'Information on training data'},
'quant_analyses': {'unitary': 'Unitary results',
'intersectional': 'Intersectional results'},
'ethical_considerations': {'sensitive_data': 'Does the model use any sensitive data (e.g., protected classes)?',
'human_life': 'Is the model intended to inform decisions about matters central to human life or flourishing - e.g., health or safety? Or could it be used in such a way?',
'mitigations': 'What risk mitigation strategies were used during model development?',
'risks_and_harms': 'What risks may be present in model usage? Try to identify the potential recipients,likelihood, and magnitude of harms. If these cannot be determined, note that they were considered but remain unknown',
'use_cases': 'Are there any known model use cases that are especially fraught?',
'additional_information': 'If possible, this section should also include any additional ethical considerations that went into model development, for example, review by an external board, or testing with a specific community.'},
'caveats_recommendations': {'caveats': 'For example, did the results suggest any further testing? Were there any relevant groups that were not represented in the evaluation dataset?',
'recommendations': 'Are there additional recommendations for model use? What are the ideal characteristics of an evaluation dataset for this model?'}}And as before, any remaining open questions can be viewed and answered using the same methods as above.